Abundance via line-transect distance-sampling when detection does not depend on covariates.
Construct the Rdistance data frame
library(Rdistance)
Loading required package: units
udunits database from C:/Users/trent/AppData/Local/R/win-library/4.4/units/share/udunits/udunits2.xml
Rdistance (v4.0.5)
# Example data (see ?sparrowDetectionData)data("sparrowDetectionData") # access example datadata("sparrowSiteData")head(sparrowDetectionData) # inspect data
# First, set study area size or desired density baseoneHectare <-set_units(1, "ha")# To save computation time, set `ci = NULL`# to compute point estimates only, i.e., abunFit <- dfuncFit |>abundEstim(area = oneHectare , ci =NULL)summary(abunFit)
Call: dfuncEstim(data = sparrowDf, dist ~ groupsize(groupsize),
likelihood = "hazrate", w.hi = whi)
Coefficients:
Estimate SE z p(>|z|)
(Intercept) 3.880324 0.1024185 37.886959 0.000000e+00
k 2.966557 0.3724577 7.964816 1.654703e-15
Convergence: Success
Function: HAZRATE
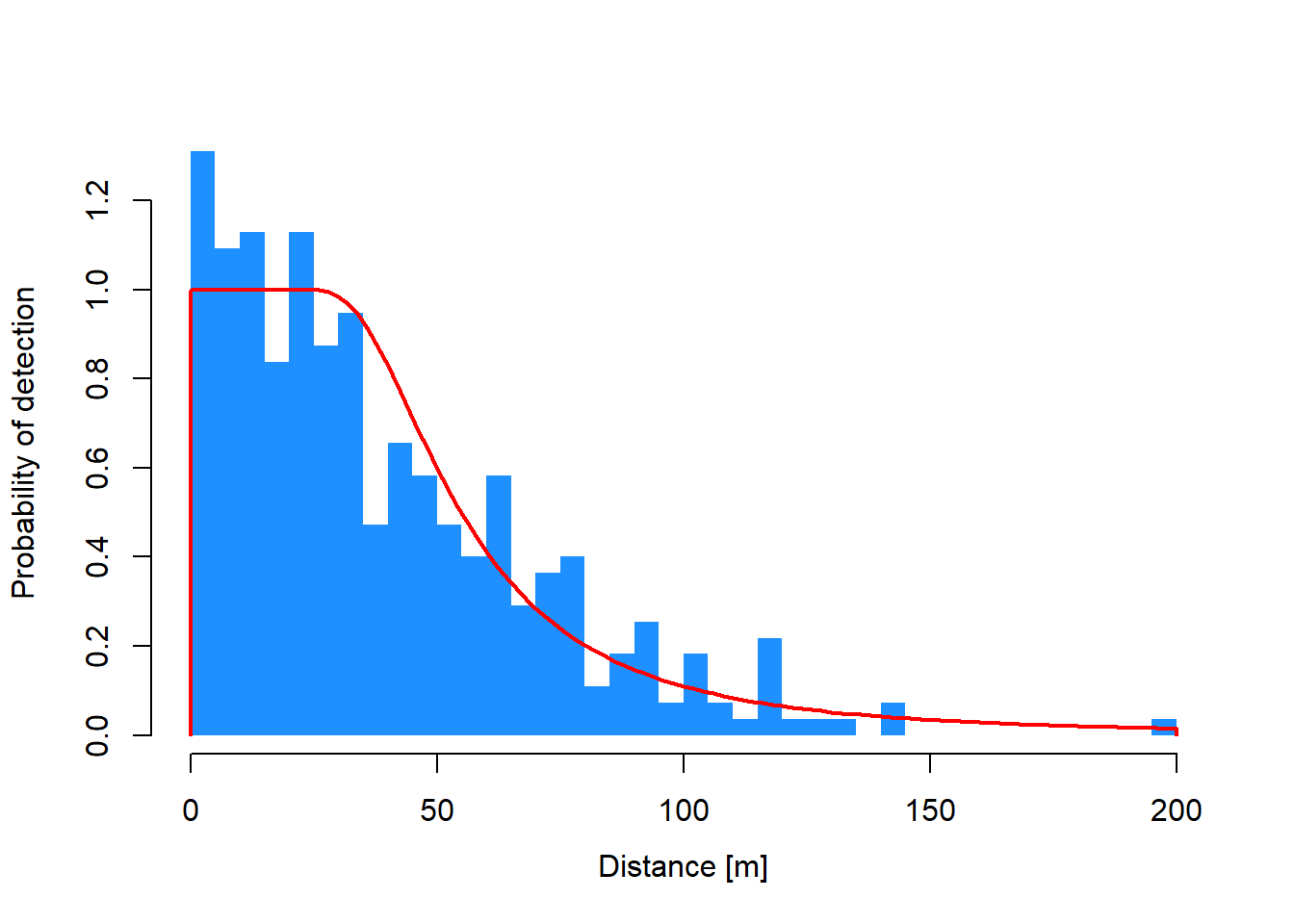
Strip: 0 [m] to 200 [m]
Effective strip width (ESW): 64.40993 [m]
Probability of detection: 0.3220496
Scaling: g(0 [m]) = 1
Log likelihood: -1647.79
AICc: 3299.614
Surveyed Units: 36000 [m]
Individuals seen: 372 in 354 groups
Average group size: 1.050847
Group size range: 1 to 3
Density in sampled area: 8.021538e-05 [1/m^2]
Abundance in 10000 [m^2] study area: 0.8021538
# Estimates are stored inside the output objectdata.frame(abunFit$estimates)
id X.Intercept. k density abundance nGroups nSeen
1 Original 3.880324 2.966557 8.021538e-05 [1/m^2] 0.8021538 354 372
area surveyedUnits avgGroupSize avgEffDistance
1 10000 [m^2] 36000 [m] 1.050847 64.40993 [m]
Density and abundance: With confidence intervals
# Set `ci =` to desired confidence level# Set `R =` to number of bootstrap iterationsabunFit <- dfuncFit |>abundEstim(area = oneHectare , ci =0.95 , R =100)summary(abunFit)
Call: dfuncEstim(data = sparrowDf, dist ~ groupsize(groupsize),
likelihood = "hazrate", w.hi = whi)
Coefficients:
Estimate SE z p(>|z|)
(Intercept) 3.880324 0.1024185 37.886959 0.000000e+00
k 2.966557 0.3724577 7.964816 1.654703e-15
Convergence: Success
Function: HAZRATE
Strip: 0 [m] to 200 [m]
Effective strip width (ESW): 64.40993 [m]
Probability of detection: 0.3220496
Scaling: g(0 [m]) = 1
Log likelihood: -1647.79
AICc: 3299.614
Surveyed Units: 36000 [m]
Individuals seen: 372 in 354 groups
Average group size: 1.050847
Group size range: 1 to 3
Density in sampled area: 8.021538e-05 [1/m^2]
95% CI: 6.156131e-05 [1/m^2] to 0.000119359 [1/m^2]
Abundance in 10000 [m^2] study area: 0.8021538
95% CI: 0.6156131 to 1.19359
Final density estimate (at the bottom of the output) is 0.8022 sparrows per hectare (95% CI: 0.6156 to 1.1936).
# Note: all bootstrap results are stored inside the output objecthead(data.frame(abunFit$B))